You Know, For Search
ES 的全称是 ElasticSearch,它是一个实时的分布式存储、搜索、分析的引擎,相比于其他的数据库来说,它更专注于搜索。
推荐学习资料
原理
为什么ES的搜索性能优于其他数据库呢?我简单梳理了一下他的原理。
首先它是一个NoSQL数据库,与传统的关系型数据库不同,NoSQL大多采用非结构化的数据结构。例如ES采用的就是文档(就是Json串)。Json全称是 Java Script Object Notation,它将一个对象转换为一个字符串来存储。我们知道一个对象有着复杂的结构,易于表示,不易存储。在关系型数据库中,是将对象的属性映射为表的字段,再进行存储,需要用到对象时,再将字段映射回对象的属性。那么我们为什么不建立一种新的数据结构来存储对象呢?Json就是这个问题的回答。我们看一个简单的Json例子:
它表示了一个person对象,包括了姓、名、年龄、介绍、兴趣等属性。Json里的属性和属性值是由键值对的方式表达的,值可以是字符串、数字、数组、对象等。
在Json的基础上,我们看看ES是如何处理搜索的:
假设我们的问题如图所示,我们需要搜索title中含有“加盟”的记录。如果是传统数据库,我们需要select所有记录,然后找出其中title含有“加盟”的。如果数据量比较大,查询频率高,我们这样做显然会很耗时。为了处理搜索这个应用场景下的问题,ES是这样一个处理流程;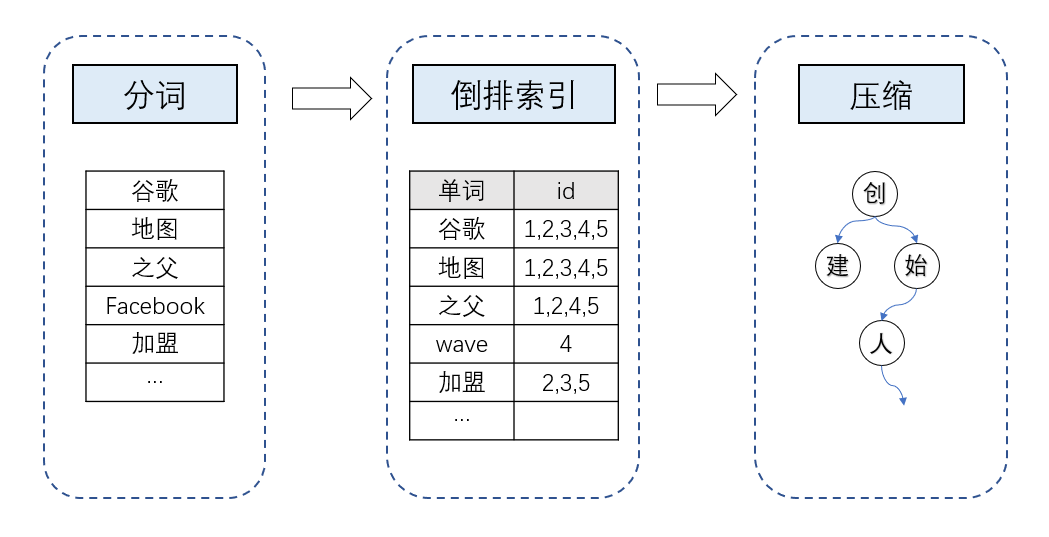
首先,对属性值进行分词,将属性值的字符串分成一个个词,然后进行倒排索引。倒排索引就是按照前面的值,统计出每个词出现的位置。例如“谷歌”在1,2,3,4,5这些文档里出现过,“加盟”在2,3,5这些文档里出现过。当我们搜索“加盟”时,ES直接返回2,3,5给我们就可以了。通过倒排索引,ES将查询成本从查询阶段挪到了插入数据阶段,极大地提高了用户的搜索体验。进一步地,由于词的数量可能比较大,全部放在内存里较为困难,因此ES将部分词的前缀拿了出来,进行压缩放在内存里,词库则放在磁盘上,我们的搜索词可以先通过内存的前缀快速找到在磁盘的存储位置,进一步提高了速度。
术语
ES里有一些术语,通常大家会将他们与关系型数据库进行对比,从而快速理解他们的意义,但实际上ES里的一些术语用关系型数据库里的术语并不能准确描述.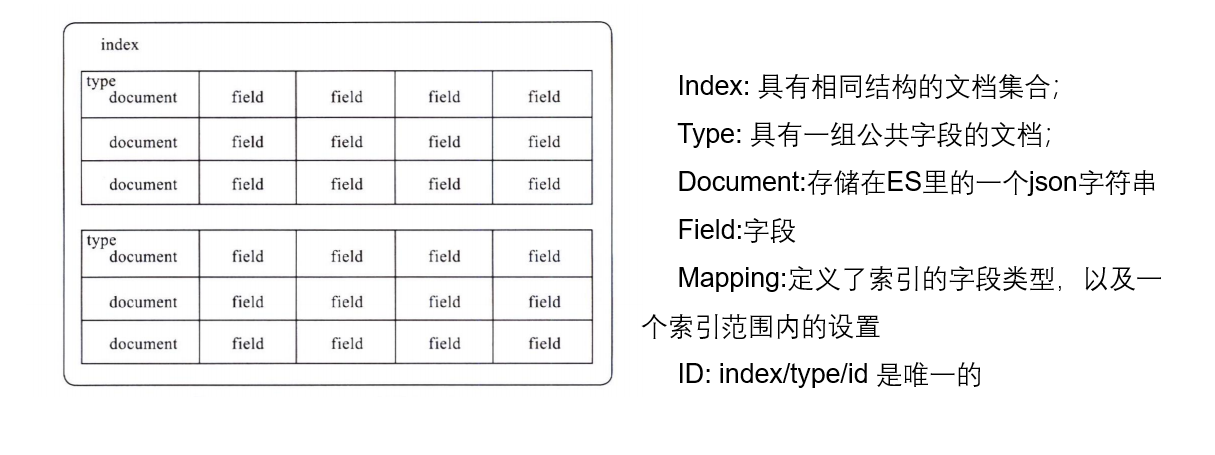
重点:
- Index是ES里最基础的术语,类似于关系型数据库里的database,有一个区别是ES里按Index进行存储,关系型数据库里按 table 进行存储。
- Type表示类型,类似于关系型数据库里的table,但是不完全一致,严格说他是具有一组公共字段的文档。上面说了ES按Index进行存储,所以同一个Index下的所有Type
在存储结构上是一样的。这意味着两个问题,第一,同一个Index下的所有Type中的同名属性必须是唯一的,例如 Type_1 的一个 name 属性是字符串类型,Type_2 的一个 name 属性是整数类型,这就会报错,因为这一个Index下只能有一个name;第二,一个Type存储时,会存储整个Index的所有字段,当同一个Index的Types区别较大时,会造成存储的稀疏,由于ES里部分的算法是基于前一个文档与后一个文档的区别,这种稀疏影响性能。所以结合这两点,使用Type时,要注意同一个索引下的Type应当结构相似。不过7.x以后,Type已经被弃用了。
分布式
ES是支持分布式的,如下图所示: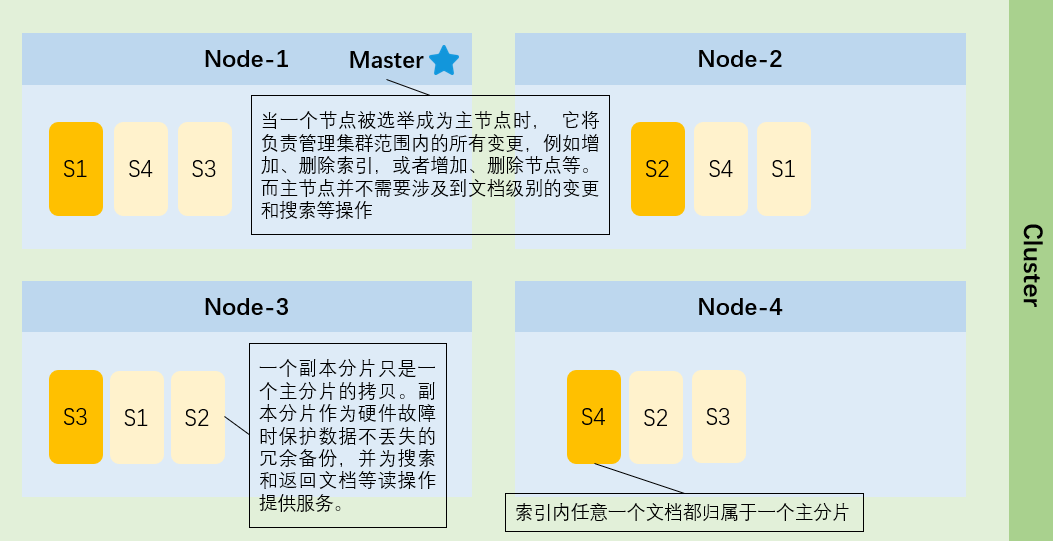
使用 Python 操作 ES
ES支持两个接口,Java接口和Http接口。很多语言都可以通过Http接口进行操作,由于我用的Python较多,因此我使用Python来简单介绍下。
导入相关包
|
|
连接ES
|
|
插入文档
|
|
可能会报警告:ElasticsearchWarning: Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone….。这是由于默认情况下,没开启安全特性,可以忽略。
插入更多文档
|
|
根据id查询
|
|
查询所有文档
|
|
对于查询来说,关键在于body参数,这个参数就是http查询是的查询体,所以后面我只写出查询体。
单字段匹配
匹配基础语法有 match 和 term, term表示精确匹配,match表示模糊匹配,我们先看term。
假设我们现在要查询 last_name 为 Smith 的员工。
可以看到查询结果为空。 原因是分析器会将”Smith”变成小写,如下所示:
|
|
可以看到分析器分析过后,”Smith”变成小写存储”smith”。因此精确匹配”Smith”查不到。
通过设置分析器我们可以改变是否大小写,从而避免这样的问题,但是我这里就不深入了。现在我们一个简单的方法就是使用小写来查询:
|
|
如果没有问题的话,应该可以查找成功。
除了term,我们还可以用模糊查询match:
|
|
单字段 多条件匹配
与term对应的是terms,可以进行单字段的多条件匹配,例如我们要查找last_name为smith或fir的员工(注意大小写):
|
|
那么match有没有matches呢,并没有,只有multi_match,但这个是多字段匹配的,如果一定要有match,可以考虑后面介绍的复杂语句。
多字段匹配
多字段匹配我们就可以用刚刚说的multi_match了,例如我们现在要查询 last_name 或者 first_name 为 Smith的员工。
|
|
另一个可以考虑的是query_string
接下来介绍一些实际用例:
查询 last_name 为 Smith 且年龄在20到30岁以内的
|
|
查询爱好攀岩的员工
|
|
可以看到 rock albums 也返回了(还是由于分词的原因)。另一个需要注意的是 _score ,这个值表示了相关性(关系型数据库没有这种特点)。
为了只返回 rock climbing,可以使用短语:
返回的结果支持高亮,使用HTML的标签标记出需要高亮的词
默认情况下并不是上面那个结果,而是下面这个错误:
RequestError(400, ‘search_phase_execution_exception’, ‘Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [interests] in order to load field data by uninverting the inverted index. Note that this can use significant memory.’)
这是由于5.x后对排序,聚合这些操作用单独的数据结构(fielddata)缓存到内存里了,需要单独开启,也就是提前修改索引的设置:
PUT megacorp/_mapping/employee/
{ “properties”: { “interests”: {“type”: “text”, “fielddata”: true } } }
换成 Python 操作如下:
查询smith的兴趣
|
|
查询每种兴趣的员工平均年龄
|
|